
Video Large Language Models (Video LLMs) have shown promising capabilities in video comprehension, yet they struggle with tracking temporal changes and reasoning about temporal relationships. While previous research attributed this limitation to the ineffective temporal encoding of visual inputs, our diagnostic study reveals that video representations contain sufficient information for even small probing classifiers to achieve perfect accuracy. Surprisingly, we find that the key bottleneck in Video LLMs' temporal reasoning capability stems from the underlying LLM's inherent difficulty with temporal concepts, as evidenced by poor performance on textual temporal question-answering tasks. Building on this discovery, we introduce the Textual Temporal reasoning Transfer (T3). T3 synthesizes diverse temporal reasoning tasks in pure text format from existing image-text datasets, addressing the scarcity of video samples with complex temporal scenarios. Remarkably, without using any video data, T3 enhances LongVA-7B's temporal understanding, yielding a 5.3 absolute accuracy improvement on the challenging TempCompass benchmark, which enables our model to outperform ShareGPT4Video-8B trained on 28,000 video samples. Additionally, the enhanced LongVA-7B model achieves competitive performance on comprehensive video benchmarks. For example, it achieves a 49.7 accuracy on the Temporal Reasoning task of Video-MME, surpassing powerful large-scale models such as InternVL-Chat-V1.5-20B and VILA1.5-40B. Further analysis reveals a strong correlation between textual and video temporal task performance, validating the efficacy of transferring temporal reasoning abilities from text to video domains.
We construct a suite of probing tasks and synthesized videos to diagnose the temporal reasoning bottleneck of Video LLMs.
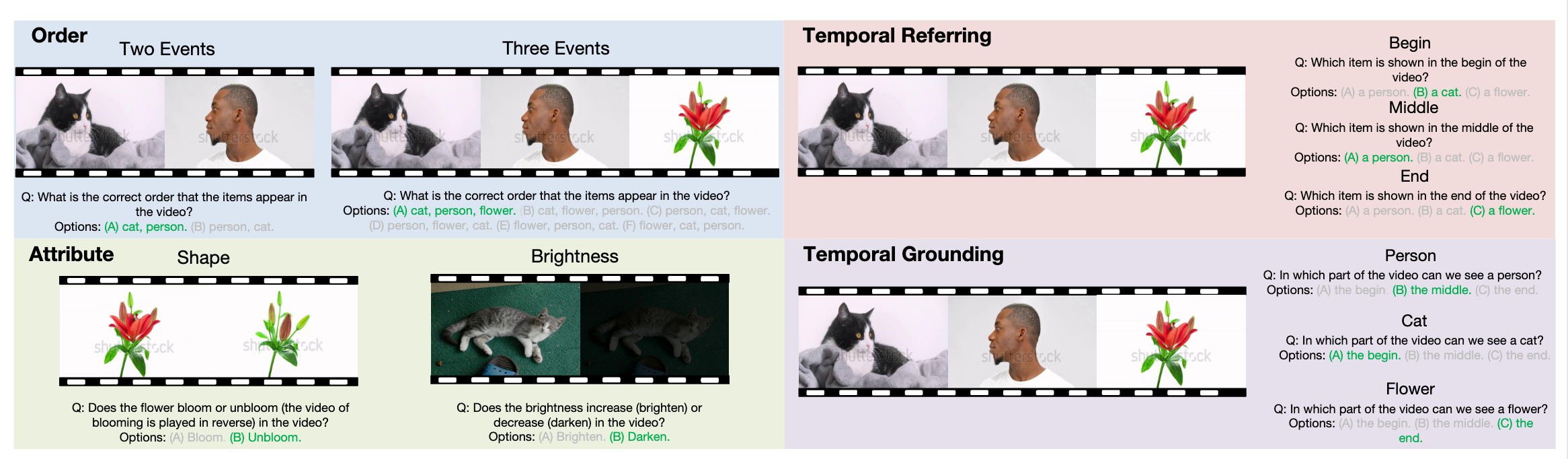
For each task, we evaluate (i) Full Video LLMs using original Video QA format (ii) Visual encodings of videos in the embedding space by training probing classifiers and (iii) Backbone LLMs with textual descriptions of the video.
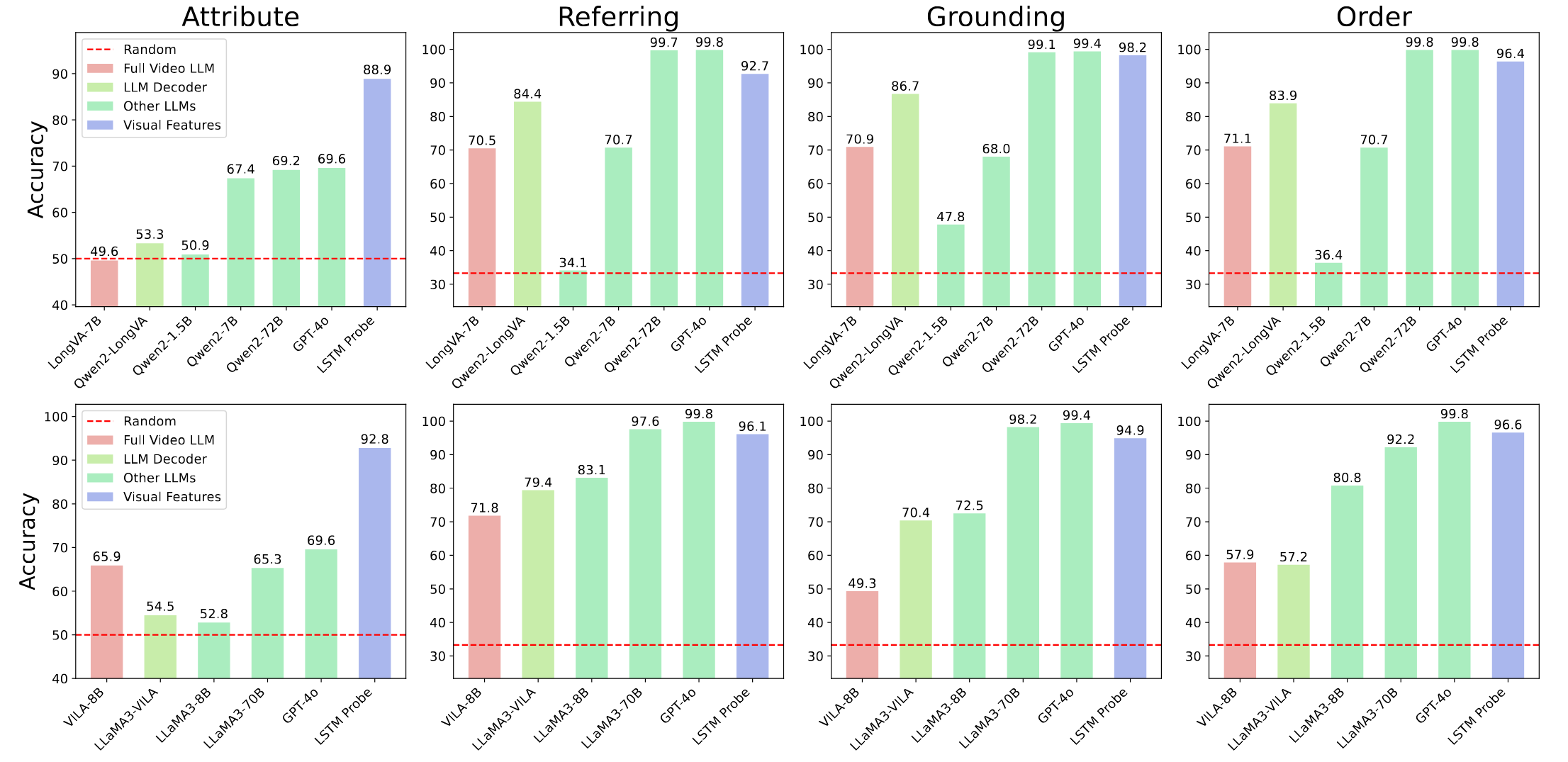
The probe on visual representations achieve > 90% accuracy in most cases, while the LLM decoders still have large room for improvement even with textual inputs, leading to the poor temporal understanding ability of Video LLMs.
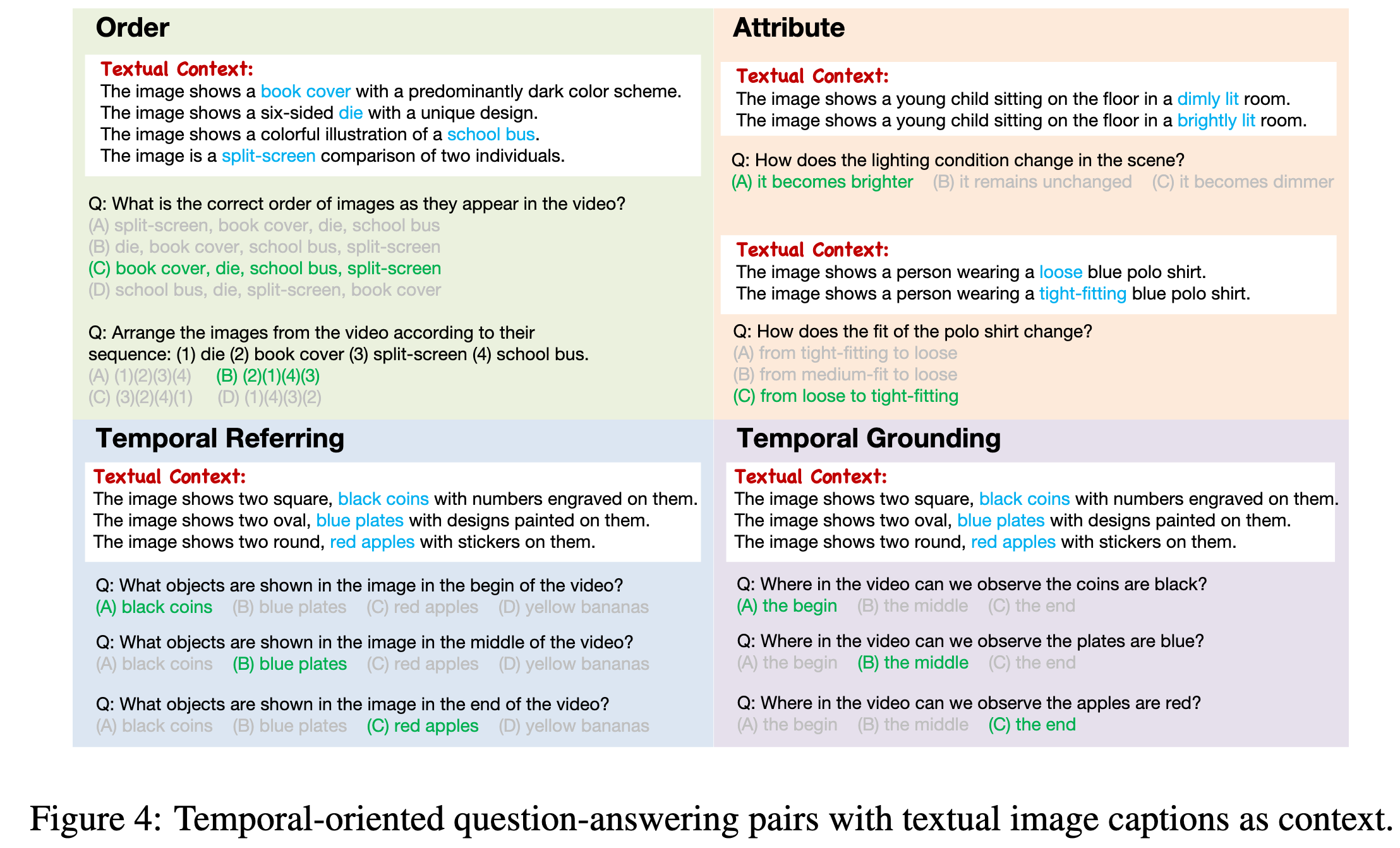
We propose T3, which synthesizes diverse temporal tasks from image captions in pure text to enhance the temporal reasoning ability of Video LLMs.
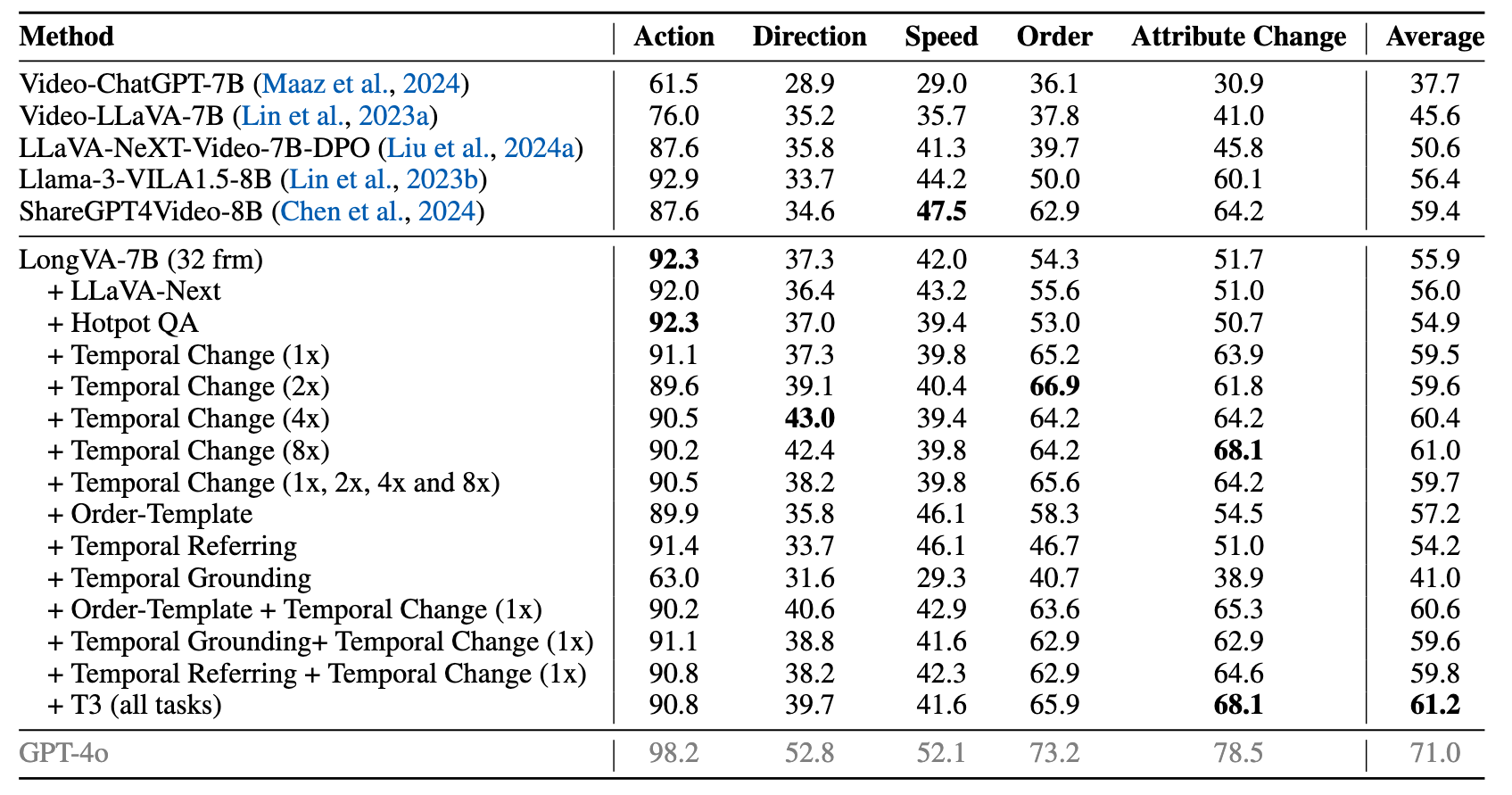
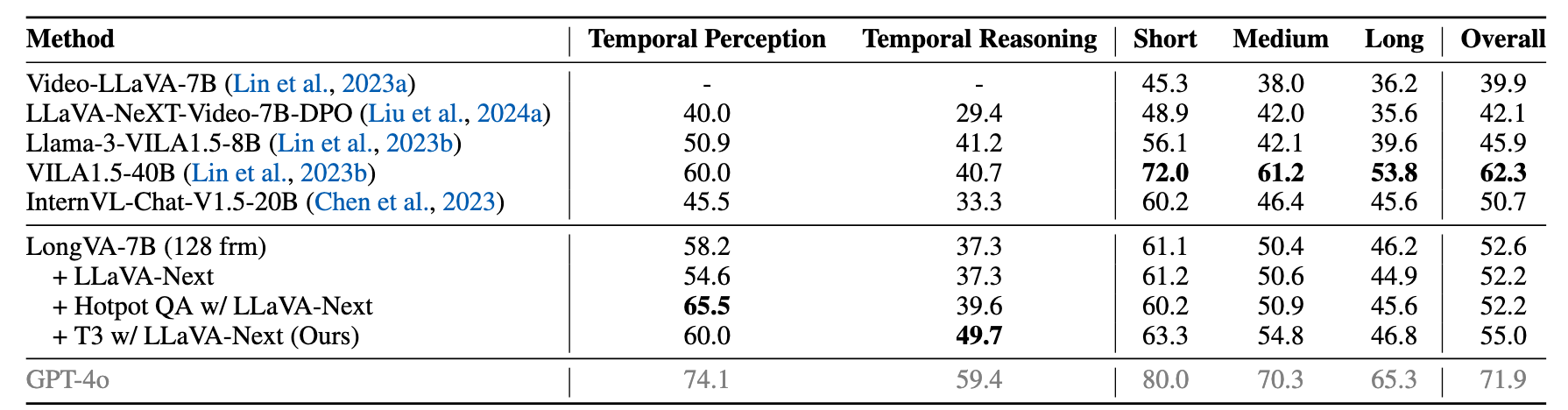
Our T3 brings clear boost of fine-grained temporal reasoning ability of LongVA-7B, which outperforms ShareGPT4Video-8B trained on 28,000 video samples on TempCompass:
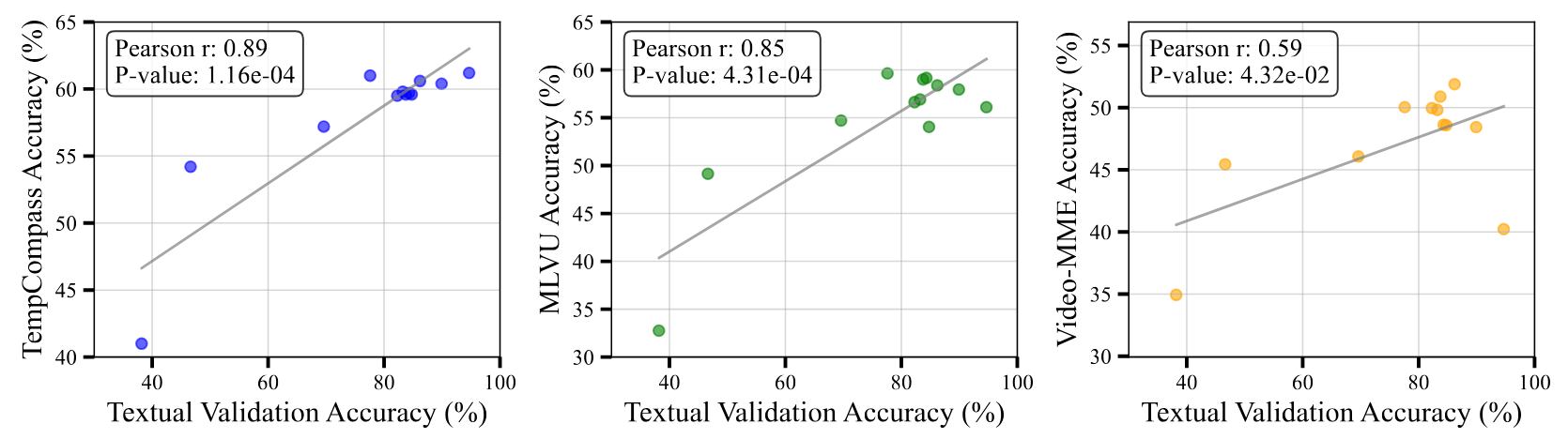
We also found the textual validation accuracy is highly correlated with the performance on video understanding benchmarks, which validates the efficacy of transferring temporal reasoning abilities from text to video domains.
T3 also improves the performance on MLVU,
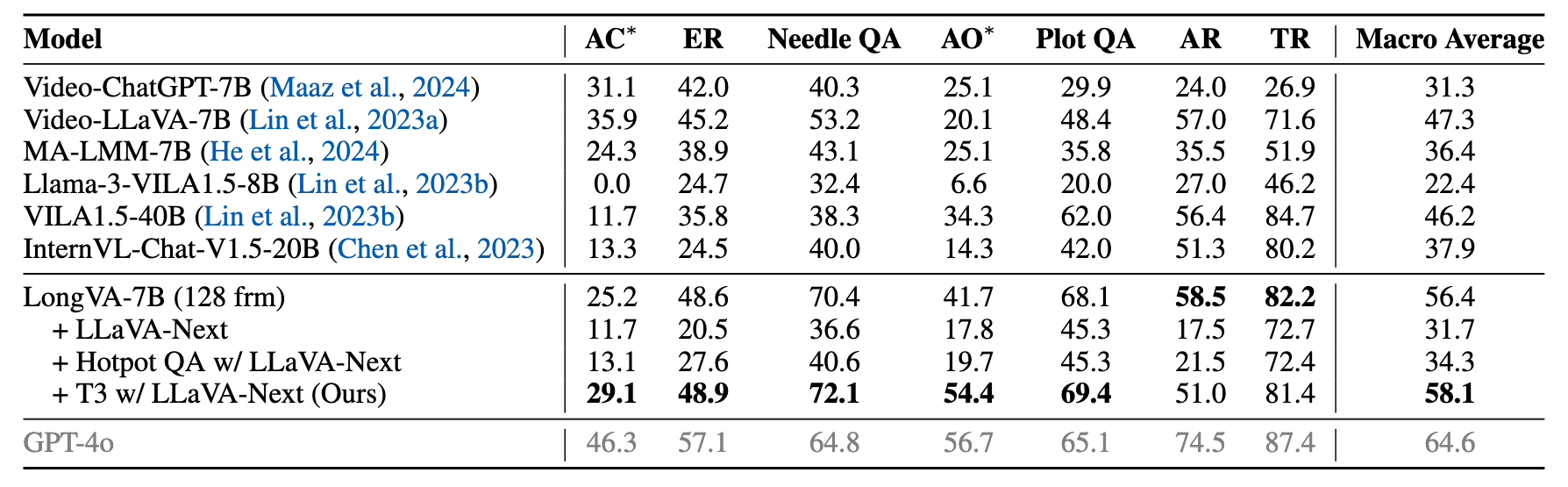
and Video-MME as well:
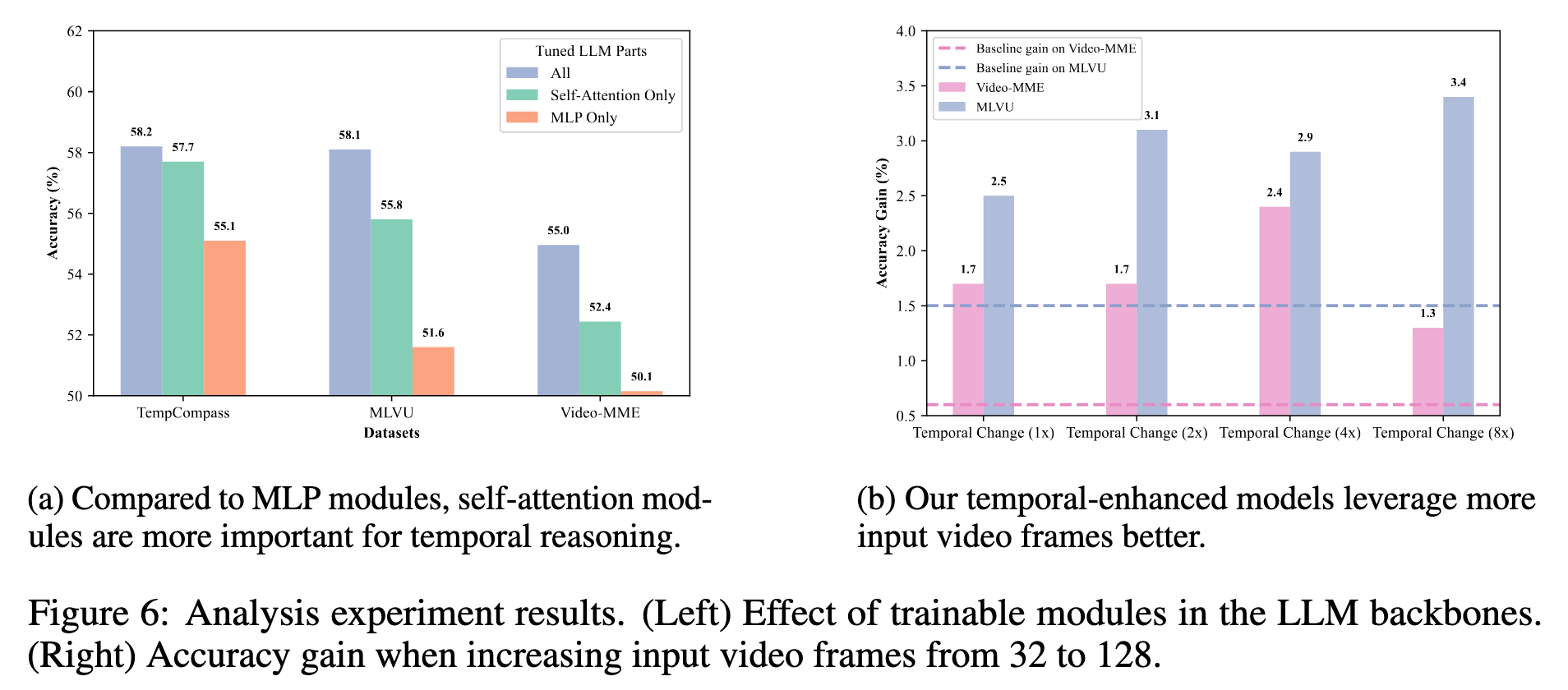
Our analysis reveals that Self-Attention modules are more important for temporal information aggregation and our method improves the utilization of more input video frames:
@inproceedings{li2025videot3,
author={Li, Lei and Liu, Yuanxin and Yao, Linli and Zhang, Peiyuan and An, Chenxin and Wang, Lean and Sun, Xu and Kong, Lingpeng and Liu, Qi},
title={Temporal Reasoning Transfer from Text to Video},
booktitle = {ICLR 2025},
publisher = {OpenReview.net},
year = {2025},
url = {https://openreview.net/forum?id=sHAvMp5J4R}
}
This website is adapted from LLaVA-VL and Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of LongVA and GPT-4.
Related Links: LongVA, TempCompass, Video-MME, MLVU